برآورد
برآورد
روشهای آمار استنباطی به منظور برآورد پارامترهای جامعه (میانگین جامعه) از طریق نمونه گیری علمی از جامعه مورد نظر بکار میرود. برای مثال اگر از جامعهای نمونه انتخاب کنیم و میانگین این نمونه را به منظور برآورد میانگین جامعه محاسبه کنیم، در واقع یک برآورد یا پیش بینی در باره میانگین جامعه از طریق نمونه انتخابی انجام دادهایم. آمار برآوردی دارای ارزش است که بدون سوگیری (Unbiased) ، با ثبات (Consistent) ، کارا (Efficient) و مکفی (Sufficent) باشد.آزمون فرض
فرضیه آماری نقطه آغاز آزمون فرض است. فرضیه آماری یک بیان مقداری در باره پارامترهای جامعه است و اصولا بدون داشتن فرضیه آماری امکان انجام یک آزمون دشوار است. فرضیه آماری به دو دسته فرض صفر (H0) و فرض خلاف (HA) بیان میشود.آزمونهای آمار استنباطی
آزمونهای آماری مورد استفاده جهت تجزیه و تحلیل اطلاعات بدست آمده از یک گروه کوچک (نمونه) و تعمیم آن به جامعه مورد نظر با توجه به مقیاس اندازه گیری متغیرها به دو گروه پارامتری و ناپارامتری تقسیم میشوند. آزمونهای پارامتری به تجزیه و تحلیل اطلاعات در سطح مقیاس فاصلهای و نسبی میپردازند که حداقل شاخص آماری آنها میانگین (Mean) و واریانس (Variance) است. در حالیکه آزمونهای نا پارامتری به تجزیه و تحلیل اطلاعات در سطح مقیاس اسمی و رتبهای میپردازند که شاخص آماری آنها میانه (Median) و نما (Mode) است.
آزمونهای پارامتری آمار استنباطی
آزمون t
آزمون t ، توزیع یا در حقیقت خانوادهای از توزیعها است که با استفاده از آنها فرضیههایی را در باره نمونه در شرایط جامعه ناشناخته است، آزمون میکنیم. اهمیت این آزمون (توزیع) در آن است که پژوهشگر را قادر میسازد با نمونههای کوچکتر (حداقل 2 نفر) اطلاعاتی در باره جامعه بدست آورد. آزمون t شامل خانوادهای از توزیعها است (برخلاف آزمون z) و اینگونه فرض میکند، که هر نمونهای دارای توزیع مخصوص به خود است، که شکل این توزیع از طریق محاسبه درجات آزادی (Degrees of Freedom) مشخص میشود. به عبارت دیگر توزیع t تابع درجات آزادی است و هر چه درجات آزادی (d.F) افزایش پیدا کند به توزیع طبیعی نزدیکتر میشود. هرچه درجات آزادی کاهش یابد، پراکندگی بیشتر میشود. خود درجات آزادی نیز تابعی از اندازه نمونه انتخابی هستند. هر چه تعداد نمونه بیشتر باشد بهتر است. از آزمون t میتوان برای تجزیه و تحلیل میانگین در پژوهشهای تک متغیری یک گروهی و دو گروهی و چند متغیری دو گروهی استفاده کرد.آزمون تحلیل واریانس
مواقعی که پژوهشگری بخواهد بیش از دو میانگین (بیش از دو نمونه) را مقایسه کند، باید از تحلیل واریانس استفاده کند. تحلیل واریانس یک روش فراگیرنده تر از آزمون t است و برخی پژوهشگران حتی وقتی مقایسه میانگینهای دو نمونه مورد نظر است از این روش استفاه میکنند. طرحهای متنوعی برای تحلیل واریانس وجود دارد و هر یک تحلیل آماری خاص خودش را طلب میکند. از جمله این طرحها میتوان به تحلیل یک عاملی واریانس (تحلیل یک طرفه) و تحلیل عاملی متقاطع واریانس ، تحلیل واریانس چند متغیری ، تحلیل کوواریانس یک متغیری و چند متغیری و …. اشاره کردآزمونهای ناپارامتری آمار استنباطی
در پژوهشهایی که در سطح مقیاسهای اسمی و رتبهای اجرا میشوند، باید از آزمونهای ناپارامتریک برای تجزیه و تحلیل اطلاعات استفاده شود. آزمونهای زیادی برای این امر وجود دارد که براساس نوع تحلیل (نیکویی برازش، همسویی دو نمونه مستقل ، همسویی دو نمونه وابسته ، همسویی K نمونه مستقل و همسویی K نمونه وابسته) و مقیاس اندازه گیری میتوان دست به انتخاب زد. از آزمونهای مورد استفاده برای پژوهشها در سطح اسمی میتوان به آزمون X2 ، آزمون تغییر مک نمار ، آزمون دقیق فیشر و آزمون کاکرن اشاره کرد. از آزمونهای مورد استفاده برای پژوهشها در سطح رتبهای میتوان به دو آزمون کولموگروف - اسمیرونف ، آزمون تقارن توزیع ، آزمون علامت ، آزمون میانه ، آزمون uمان – ویتنی ، آزمون تحلیل واریانس دو عاملی فریدمن و … اشاره کرد.
+ نوشته شده در سه شنبه دوم بهمن ۱۳۸۶ ساعت 19:51 توسط mostafa
|
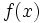 مقدار توزیع احتمال آن به ازای x باشد، مقدار مورد انتظار X برابر است با
مقدار توزیع احتمال آن به ازای x باشد، مقدار مورد انتظار X برابر است با
 ممکن است
ممکن است  باشد. بنابراین حرف X قرار گرفته داخل پرانتز در تعریف
باشد. بنابراین حرف X قرار گرفته داخل پرانتز در تعریف
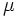 نشان میدهیم بعبارت دیگر
نشان میدهیم بعبارت دیگر  نشان میدهیم مقدار امید
نشان میدهیم مقدار امید
 با تشکر از کسانی که با نظرات و انتقادهای خود باعث بالا رفتن کیفیت وبلاگ می شوند.
با تشکر از کسانی که با نظرات و انتقادهای خود باعث بالا رفتن کیفیت وبلاگ می شوند.